 >
>
Gráfico de Conceptos & Resumen usando Claude 3 Opus | Chat GPT4o | Llama 3:
Resumen:
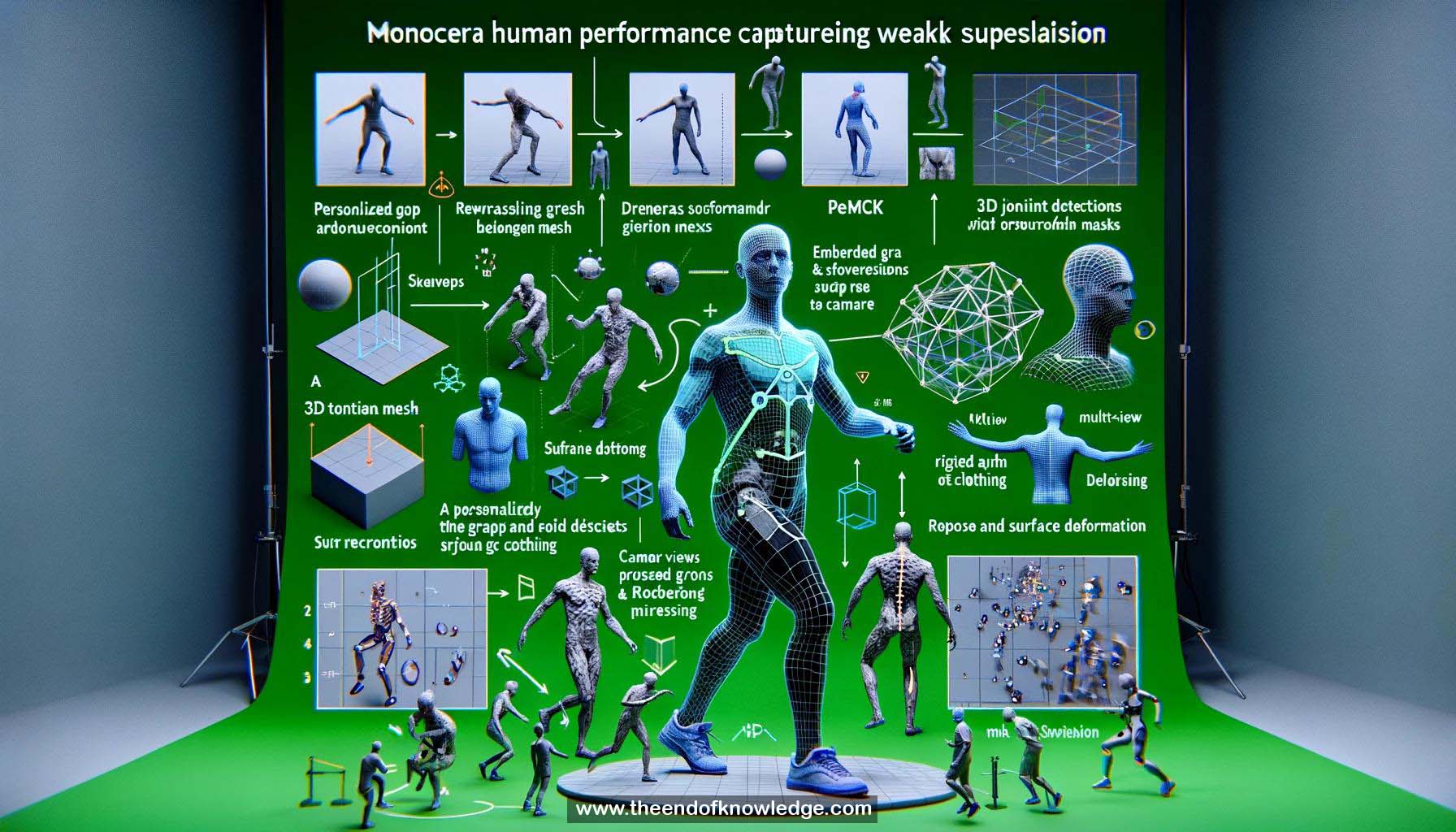
1.- DeepCAP: enfoque de captura de rendimiento humano monocular usando una única cámara RGB.
2.- Captura pose y deformación de ropa para personajes virtuales realistas.
3.- Entrenamiento débilmente supervisado evita procesamiento de datos complicado.
4.- La configuración monocular es desafiante debido a ambigüedades de profundidad y problema de alta dimensión.
5.- Trabajo previo: modelos de cuerpo paramétricos sin plantilla y métodos basados en plantillas.
6.- DeepCAP utiliza una malla de plantilla 3D personalizada con un gráfico embebido y esqueleto.
7.- PoseNet regresa la pose del esqueleto, y DepthNet regresa la deformación de la superficie en pose canónica.
8.- Las redes son débilmente supervisadas con detecciones de juntas 2D multivista y máscaras de primer plano.
9.- Se requieren módulos diferenciables de 3D a 2D para evaluación de pérdida.
10.- Configuración de captura: estudio de pantalla verde multicámara para entrenamiento.
11.- PoseNet produce posiciones de puntos de referencia 3D en cámara y espacio relativo a la raíz.
12.- Capa de alineación global calcula y aplica rotación y traslación para posiciones de puntos de referencia 3D globales.
13.- Pérdida de puntos clave dispersos multivista asegura que los puntos de referencia 3D se proyecten en detecciones de juntas 2D.
14.- DepNet regresa ángulos de rotación por nodo y traslaciones del gráfico embebido.
15.- Capa de deformación combina pose regresada y deformación usando deformación embebida y skinning de cuaterniones duales.
16.- Capa de alineación global se aplica para obtener vértices y puntos de referencia globales.
17.- Pérdida de puntos clave dispersos multivista se aplica para marcadores posados y deformados.
18.- Pérdida de silueta impone que la silueta del modelo coincida con la silueta de la imagen para supervisión densa de vértices.
19.- Comparación con LifeCap muestra mejora en pose 3D y deformación plausible de superficies invisibles.
20.- Comparación con métodos de superficie implícita demuestra geometría consistente a lo largo del tiempo y evita extremidades faltantes.
21.- Intersección sobre unión multivista mide la precisión de reconstrucción de superficie.
22.- DeepCAP supera trabajos previos al considerar deformaciones de ropa y predicción consistente de deformación de tela 3D.
23.- Entrenamiento débilmente supervisado usando detecciones de juntas 2D multivista y máscaras de primer plano.
24.- Módulos diferenciables de 3D a 2D permiten evaluación de pérdida durante el entrenamiento.
25.- Se utiliza una malla de plantilla 3D personalizada con gráfico embebido y esqueleto para regresión de pose y deformación.
26.- PoseNet y DepthNet son las dos principales redes en el enfoque DeepCAP.
27.- Capa de alineación global asegura posiciones de puntos de referencia 3D globales para cálculo de pérdida.
28.- Capa de deformación combina pose regresada y deformación usando deformación embebida y skinning de cuaterniones duales.
29.- Pérdida de silueta y pérdida de puntos clave dispersos multivista proporcionan supervisión densa y dispersa, respectivamente.
30.- DeepCAP logra captura de rendimiento humano realista con geometría consistente y deformación de ropa desde una única cámara RGB.
Bóveda de Conocimiento construida por David Vivancos 2024