 >
>
Gráfico de Conceptos & Resumen usando Claude 3 Opus | Chat GPT4o | Llama 3:
Resumen:
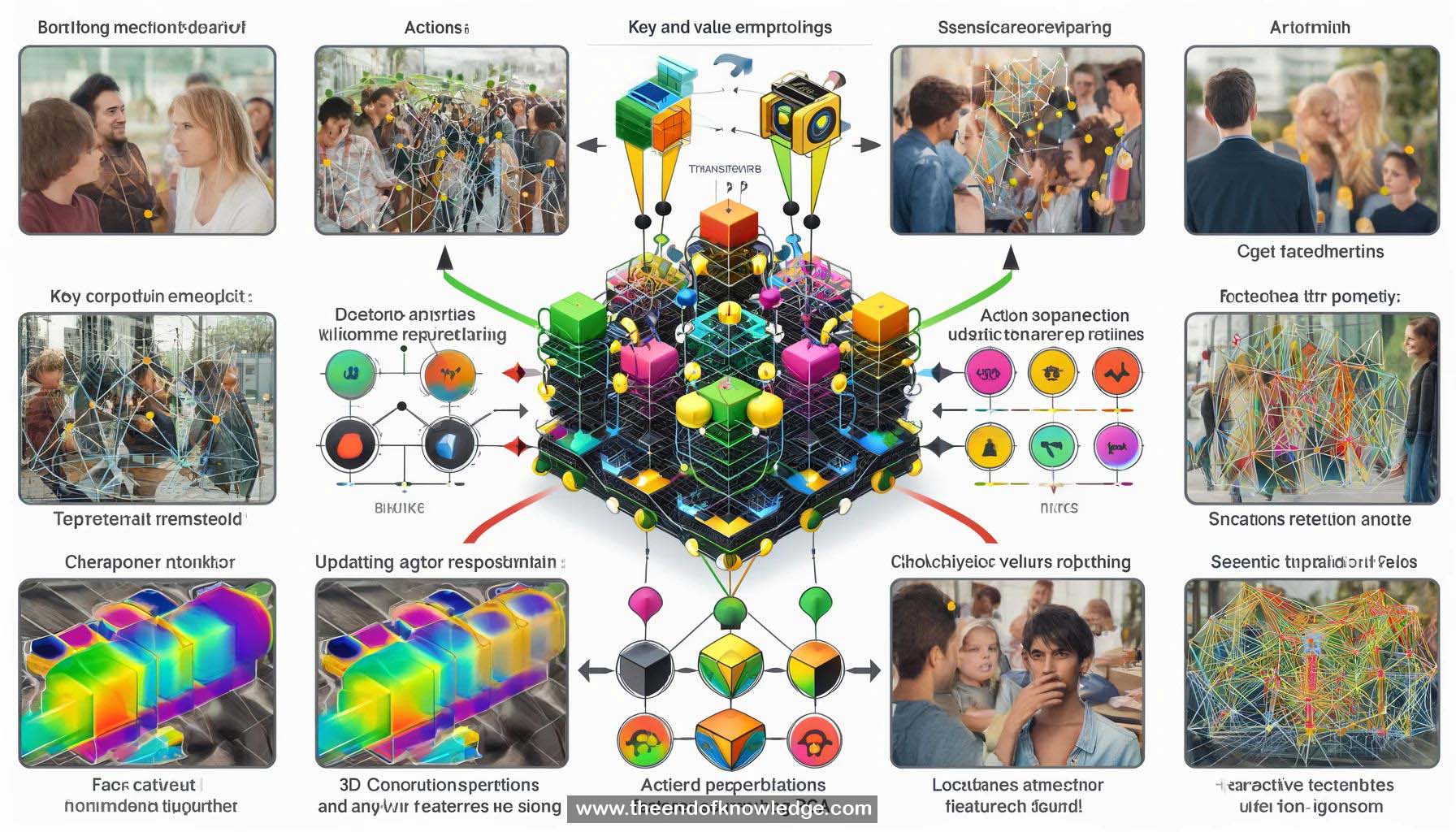
1.- La Red de Transformadores de Acción de Video tiene como objetivo localizar actores y reconocer sus acciones en clips de video.
2.- La detección de acción espacio-temporal es el término técnico para esta tarea, experimentado en el conjunto de datos AY.
3.- La solución estándar implica extraer características de convolución 3D, características del cuadro central y usar una red de propuestas de región para ubicaciones de actores.
4.- Reconocer acciones a menudo requiere mirar más allá de solo la persona, enfocándose en otras personas y objetos en la escena.
5.- Se propone una solución basada en auto-atención utilizando arquitectura de transformador para codificar el contexto para la representación del actor.
6.- La representación inicial del actor se utiliza para extraer regiones relevantes de la representación completa del video.
7.- La representación de video se proyecta en embeddings de clave y valor, y la representación del actor se utiliza para la atención de producto punto.
8.- La suma ponderada de valores se añade de nuevo a las características originales del actor, creando una representación actualizada del actor.
9.- El bloque de transformador de acción toma la representación inicial del actor, codifica el contexto del video y produce una representación actualizada del actor.
10.- Los bloques de transformador de acción se conectan después de la representación inicial del actor, junto con las características del video.
11.- Múltiples capas de bloques de transformador de acción pueden organizarse arbitrariamente, por ejemplo, una configuración de dos por tres.
12.- La característica final se entrena para la pérdida de regresión de clasificación, similar a FasterR-CNN, utilizando una cabeza de transformador de acción.
13.- Reemplazar la cabeza i3D con el transformador de acción dio una mejora del 4% en el rendimiento; usar ambos juntos produjo los mejores resultados.
14.- El modelo logró un rendimiento de vanguardia en el momento de la publicación.
15.- Los embeddings de clave y valor en los bloques de transformador de acción pueden visualizarse usando PCA y codificación de color.
16.- El modelo aprende implícitamente a rastrear personas en el video, tanto a nivel semántico como de instancia.
17.- Una cabeza de transformador de acción rastrea personas semánticamente proyectándolas al mismo embedding, mientras que otra rastrea a nivel de instancia.
18.- Los mapas de atención muestran que el modelo se enfoca en las caras, manos y objetos de otras personas en la escena.
19.- El modelo rinde bien para la mayoría de las clases de acción comunes.
20.- Resultados adicionales demuestran embeddings a nivel semántico e instancia, y atención enfocándose en personas y objetos relevantes.
Bóveda de Conocimiento construida porDavid Vivancos 2024